Inteligência Artificial e seus Conceitos-Chave: Um Guia Técnico e Didático
Inteligência artificial
Introdução
A Inteligência Artificial (IA) revolucionou a forma como interagimos com tecnologia. De assistentes pessoais a sistemas que geram imagens, a IA tornou-se parte fundamental de soluções modernas. Este artigo tem como objetivo explicar, de forma técnica e didática, os principais conceitos que formam a base dessa tecnologia: IA, Machine Learning, Deep Learning, Redes Neurais, LLMs, RAG, Visão Computacional, IA Generativa, Fine-Tuning, Model Context Protocol (MCP), entre outros.
1. Inteligência Artificial (IA)
IA é o campo da computação que busca criar sistemas capazes de simular comportamentos inteligentes, como reconhecimento de padrões, tomada de decisão, aprendizado e resolução de problemas.
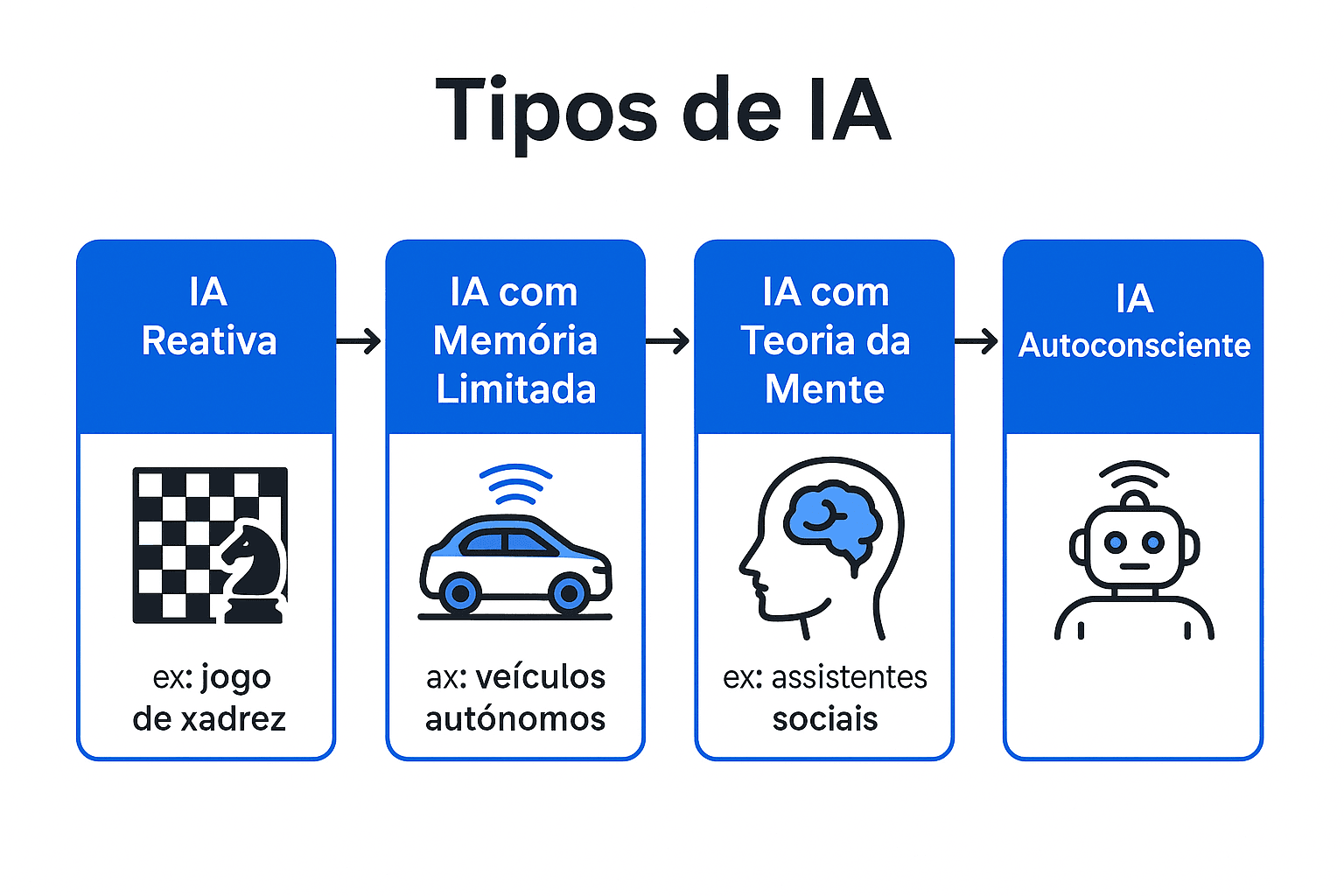
1.1 Tipos de IA
IA Específica (Narrow AI): especializada em uma única tarefa específica, como reconhecimento de voz, detecção de fraudes ou recomendação de filmes. Essa é a forma mais comum de IA presente atualmente em sistemas comerciais e industriais.
IA Generativa: subsetor da IA específica, focada em criar novos conteúdos como texto, imagens ou áudios com base em padrões aprendidos. Ver seção 1.2.
IA Geral (AGI): refere-se à capacidade teórica de uma IA realizar qualquer tarefa cognitiva que um ser humano consiga executar, com flexibilidade e autonomia. Não há aplicações práticas até o momento.
IA Reativa: apenas reage a estímulos sem armazenar memórias (ex.: Deep Blue da IBM).
IA com Memória Limitada: consegue aprender com dados recentes e experiências (ex.: carros autônomos que se adaptam ao tráfego).
IA com Teoria da Mente: conceito em desenvolvimento que visa permitir que sistemas entendam emoções, crenças e intenções humanas.
IA Autoconsciente: estágio hipotético futuro onde a IA teria consciência de si própria, identidade e motivações. Ainda inexistente e amplamente debatido na filosofia da IA.
1.2 IA Generativa
IA generativa refere-se a sistemas capazes de criar novos conteúdos com base em padrões aprendidos. Esses sistemas não apenas analisam ou classificam dados, mas também geram saídas originais e inéditas em diversos formatos como texto, imagem, áudio e vídeo. A principal característica desses modelos é sua habilidade de gerar amostras que seguem a distribuição estatística dos dados de treinamento, mantendo coerência e criatividade.
Modelos mais utilizados:
GANs (Generative Adversarial Networks): consistem em dois modelos que se enfrentam em um processo competitivo: um gerador tenta criar exemplos convincentes, enquanto um discriminador tenta distinguir entre dados reais e gerados. São amplamente usados para gerar imagens de alta qualidade, vídeos sintéticos, rostos humanos realistas e até mesmo amostras químicas.
Diffusion Models: baseados em processos de difusão e reversão do ruído. Começam com uma imagem completamente ruidosa e aprendem a "remover" esse ruído para gerar uma imagem limpa e realista. Modelos como o DALL-E 2 e o Stable Diffusion utilizam essa abordagem.
LLMs com capacidade generativa: como o ChatGPT e Claude, que são capazes de gerar textos longos e coesos, simular diálogos humanos, criar histórias, artigos, resumos, roteiros, entre outros. São treinados em grandes volumes de texto utilizando aprendizado auto-supervisionado.
Exemplos de uso:
Texto: geração automática de artigos jornalísticos, legendas, descrições de produtos, scripts de vendas.
Imagem: ilustrações publicitárias, design de produtos, avatares personalizados.
Áudio e Voz: síntese de vozes humanas, dublagens automáticas, criação de trilhas sonoras.
Vídeo: geração de cenas realistas, animações automáticas, deepfakes controlados para fins legítimos.
A IA generativa está sendo usada não apenas para automação criativa, mas também como ferramenta de prototipagem, personalização em massa, e criação de conteúdo para educação, marketing e entretenimento
2. Machine Learning (Aprendizado de Máquina)
Machine Learning é o processo pelo qual computadores aprendem a partir de dados. Ao invés de depender de regras fixas programadas manualmente, os modelos de ML são treinados a partir de exemplos para generalizar e tomar decisões com base em novos dados. O objetivo principal é construir modelos que possam identificar padrões complexos, realizar previsões ou tomar decisões automatizadas.
O processo de Machine Learning geralmente envolve:
Coleta e limpeza de dados
Engenharia de atributos (feature engineering)
Seleção de modelo
Treinamento e validação
Teste e ajuste de hiperparâmetros
Avaliação de desempenho
2.1 Tipos de Aprendizado
Supervisionado: o modelo aprende a partir de pares entrada-saída, onde cada exemplo tem um rótulo conhecido. Exemplo: classificação de e-mails como spam ou não spam, previsão de preços imobiliários com base em características como localização e metragem.
Não supervisionado: não existem rótulos nos dados. O modelo tenta identificar padrões ocultos, como agrupamentos ou distribuições de probabilidade. Exemplo: segmentação de clientes com base em comportamento de compra.
Aprendizado por reforço (Reinforcement Learning): um agente aprende interagindo com o ambiente, recebendo recompensas ou punições com base nas ações tomadas. Muito usado em jogos, robótica e sistemas de decisão sequencial. Exemplo: AlphaGo aprendendo a jogar Go por simulações.
2.2 Algoritmos comuns
Regressão Linear: técnica estatística usada para prever um valor contínuo com base em uma ou mais variáveis independentes. Exemplo: prever o valor de uma casa com base em metragem e localização.
SVM (Support Vector Machines): cria um hiperplano de separação ótimo entre classes, maximizando a margem entre os pontos de dados. Eficiente em espaços de alta dimensão e útil para tarefas de classificação binária ou multiclasse.
Árvores de Decisão: estruturas ramificadas que tomam decisões com base em condições sucessivas. Fáceis de interpretar e aplicar, são frequentemente usadas em problemas de classificação e regressão. Variantes populares incluem Random Forests e Gradient Boosted Trees.
K-Means: algoritmo de clusterização não supervisionado que agrupa os dados em "k" clusters, onde cada ponto pertence ao grupo com o centróide mais próximo. Muito usado em segmentação de clientes e análise exploratória.
Redes Bayesianas: modelos probabilísticos gráficos que representam relações de dependência entre variáveis. Úteis para tomada de decisão sob incerteza.
Naive Bayes: classificador baseado no Teorema de Bayes, com a suposição de independência entre as variáveis. Extremamente rápido e eficaz para problemas como filtragem de spam.
K-Nearest Neighbors (KNN): classifica um novo ponto com base na maioria dos "k" vizinhos mais próximos no espaço de características. Simples, mas pode ser computacionalmente custoso em conjuntos grandes.
Redes Neurais Artificiais (ANNs): embora mais associadas a deep learning, redes com poucas camadas também são consideradas algoritmos tradicionais de ML.
2.3 AutoML
AutoML automatiza tarefas como seleção de modelo, ajuste de hiperparâmetros, validação cruzada e engenharia de atributos, tornando o ML mais acessível a não especialistas. Plataformas como Google AutoML, Auto-sklearn e H2O.ai permitem que usuários testem múltiplas abordagens com esforço reduzido, democratizando o uso de IA.
2.4 Aprendizado Auto-Supervisionado
Método onde os próprios dados fornecem os rótulos, sem intervenção humana. Muito utilizado no treinamento de LLMs e modelos de visão computacional. Um exemplo comum é mascarar uma parte da entrada (como uma palavra ou região da imagem) e treinar o modelo para prever esse elemento ausente, como ocorre nos pré-treinamentos de BERT ou MAE (Masked Autoencoders).
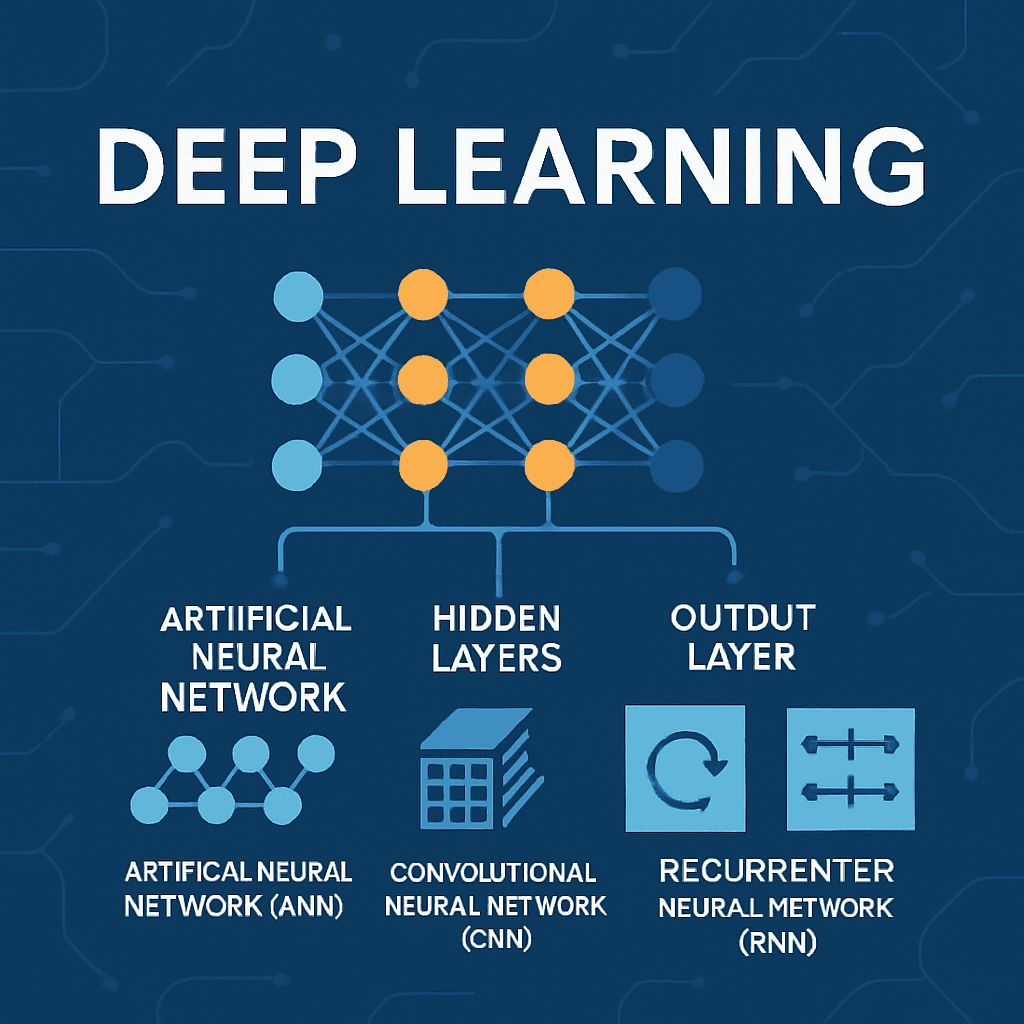
3. Deep Learning (Aprendizado Profundo)
Deep Learning é uma especialização do Machine Learning baseada em redes neurais artificiais com várias camadas ocultas. Essas camadas permitem ao modelo aprender representações hierárquicas dos dados: da informação bruta até padrões mais complexos e abstratos. Esse tipo de aprendizado é ideal para tarefas que envolvem grandes volumes de dados e relações não lineares.
Modelos de deep learning exigem grandes volumes de dados e poder computacional, mas têm apresentado resultados superiores em tarefas como reconhecimento de imagem, voz, linguagem natural e jogos.
3.1 Redes Neurais Artificiais
As redes neurais artificiais simulam o funcionamento do cérebro humano através de unidades chamadas neurônios artificiais. Cada neurônio recebe entradas, realiza uma soma ponderada e aplica uma função de ativação. Quando combinados em camadas, esses neurônios formam sistemas altamente expressivos.
Componentes principais:
Camada de entrada: recebe os dados brutos do problema.
Camadas ocultas: executam transformações não lineares para extrair padrões cada vez mais complexos.
Camada de saída: gera a previsão final (uma classe, probabilidade, valor, etc).
Pesos e viés: parâmetros ajustados durante o treinamento.
Funções de ativação: introduzem não linearidade ao modelo. Exemplos: ReLU (linear por partes), Sigmoid (ativação suavizada entre 0 e 1), Tanh.
Tipos de Redes Neurais:
ANN (Artificial Neural Networks): redes feedforward tradicionais, usadas para classificação e regressão. Têm aplicações diversas, desde predição de risco até reconhecimento de padrões simples.
CNN (Convolutional Neural Networks): projetadas para processar dados com estrutura em grade, como imagens. Utilizam filtros convolucionais para extrair bordas, texturas e formas. Usadas em diagnóstico médico por imagem, reconhecimento facial, detecção de objetos, etc.
RNN (Recurrent Neural Networks): ideais para dados sequenciais, como texto ou áudio. Mantêm um estado interno (memória) entre entradas sucessivas, permitindo que aprendam dependências temporais. Modelos derivados incluem LSTM (Long Short-Term Memory) e GRU.
Transformers: arquitetura baseada em mecanismos de atenção, permitindo que o modelo avalie a relevância de cada parte da entrada em relação às demais. Superaram as RNNs em tarefas de linguagem natural e são a base para os LLMs (como GPT).
3.2 Computação Paralela em Deep Learning
O treinamento e a inferência de modelos de deep learning dependem fortemente da execução paralela em múltiplos processadores ou GPUs. Isso se deve à alta complexidade computacional envolvida nas operações matriciais massivas realizadas por redes neurais profundas, especialmente durante o backpropagation.
Tecnologias e Ferramentas:
CUDA: API da NVIDIA que permite a execução de código em GPUs, acelerando cálculos matemáticos intensivos.
TensorFlow + XLA: compilador para acelerar operações em TensorFlow otimizando o grafo computacional para execução em múltiplas arquiteturas.
PyTorch + TorchScript: ferramenta que permite compilar modelos PyTorch para execução eficiente em ambientes de produção, inclusive com suporte a GPU.
Essa infraestrutura é crítica para possibilitar o treinamento de modelos de larga escala, como os usados em visão computacional, linguagem natural e simulações físicas.
4. Processamento de Linguagem Natural (NLP)
É a área da IA voltada para o entendimento, interpretação e geração da linguagem humana. Utiliza desde técnicas estatísticas clássicas até abordagens modernas baseadas em deep learning, como redes neurais recorrentes e Transformers. NLP é essencial para tarefas como tradução automática, análise de sentimento, chatbots e assistentes virtuais.
4.1 LLM (Large Language Models)
São modelos de linguagem com bilhões (ou trilhões) de parâmetros treinados em grandes volumes de texto. Esses modelos aprendem a prever a próxima palavra em uma sequência textual com base no contexto anterior, o que permite gerar frases coerentes e contextualmente relevantes.
Modelos conhecidos:
GPT (OpenAI): especializado em geração de texto de forma autoregressiva.
BERT (Google): focado em tarefas de classificação e compreensão textual, usando codificação bidirecional.
LLaMA (Meta): eficiente e voltado a pesquisas e aplicações privadas.
Claude (Anthropic): prioriza segurança e robustez em geração de linguagem.
Capacidades dos LLMs:
Tradução multilíngue
Resumo automático de documentos
Geração de código
Respostas contextuais e conversacionais
Classificação de sentimentos e intenção
Esses modelos são usados em chatbots, mecanismos de busca, plataformas de produtividade, atendimento ao cliente, e ferramentas de geração automatizada de conteúdo.
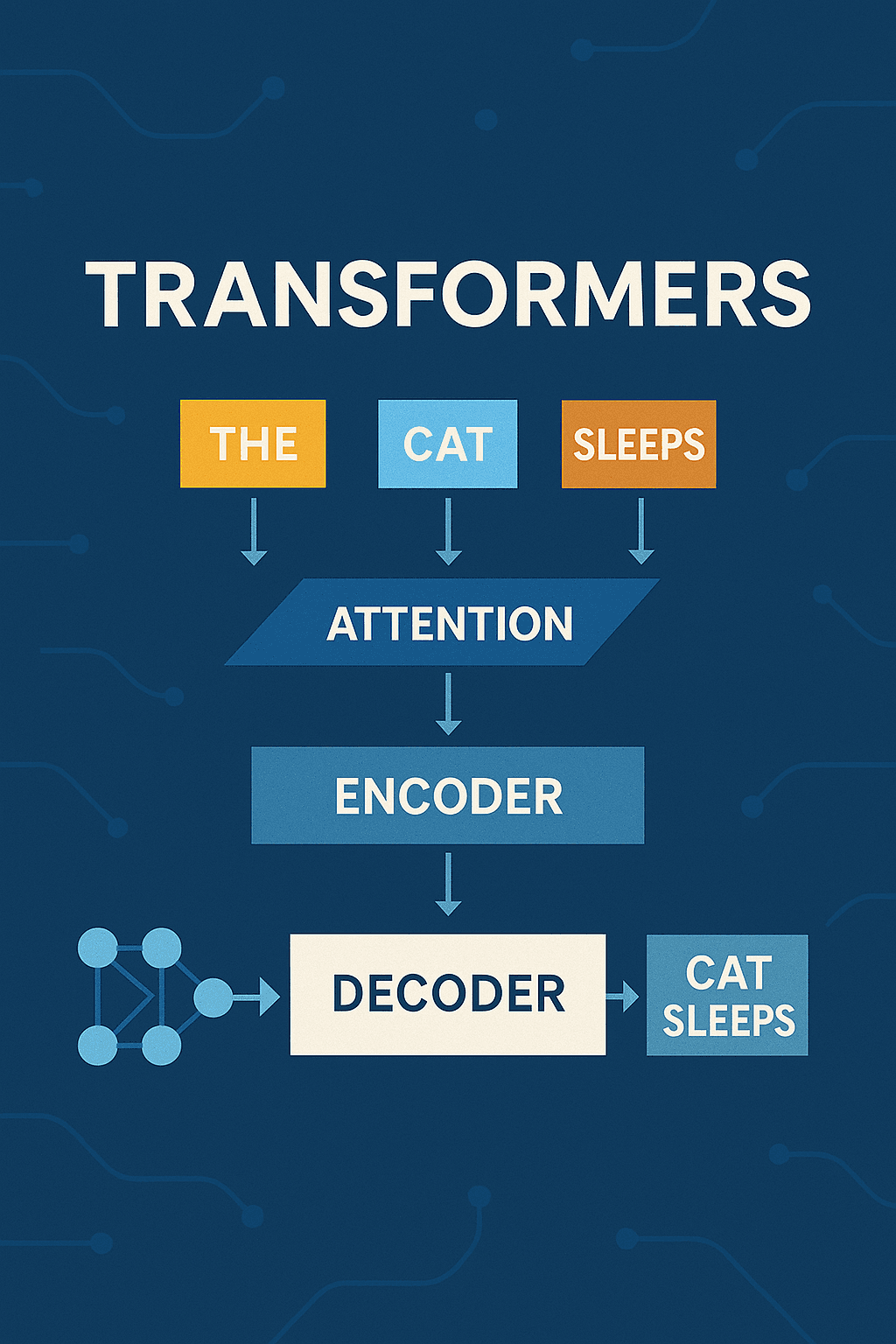
4.2 Transformers
É a arquitetura subjacente à maioria dos LLMs modernos. Baseia-se em mecanismos de atenção (especialmente atenção multi-cabeça) que permitem ao modelo avaliar a importância relativa de cada palavra em uma sequência, independentemente da sua posição.
Vantagens:
Permite paralelismo no treinamento, ao contrário das RNNs
Lida bem com sequências longas
Capta dependências de longo alcance
Flexível e adaptável a múltiplas tarefas via fine-tuning
Transformers são utilizados tanto no encoder (ex.: BERT) quanto no decoder (ex.: GPT), e em arquiteturas encoder-decoder (ex.: T5, BART).
4.3 RAG (Retrieval-Augmented Generation)
Estratégia que combina geração de linguagem com recuperação de informações externas. Em vez de depender exclusivamente do conhecimento "memorizado" no modelo, o RAG permite que o modelo busque documentos ou trechos relevantes antes de gerar a resposta.
Etapas:
Recuperação de contexto (via motor de busca vetorial, Elasticsearch, FAISS, etc.)
Geração condicionada aos trechos recuperados
Aplicações:
Chatbots com base de conhecimento empresarial
Assistentes jurídicos ou técnicos
Sistemas de resposta a perguntas com base em documentos internos
Essa abordagem aumenta a precisão e reduz a "alucinação" de fatos.
4.4 Fine-Tuning
Processo de ajuste fino de um modelo pré-treinado para torná-lo mais eficaz em uma tarefa ou domínio específico. É feito utilizando um conjunto de dados menor e altamente representativo do contexto desejado.
Benefícios:
Adaptação do modelo à linguagem ou jargão específico
Melhora de performance em tarefas específicas (ex.: jurídico, saúde, finanças)
Redução de custos comparado ao treinamento do zero
Técnicas comuns:
Fine-tuning completo de todos os parâmetros
Adição de cabeçotes de tarefa específicos (e.g., classificação, QA)
Fine-tuning permite especializar modelos fundacionais para casos de uso reais com menos dados, menos tempo e menos processamento.
4.5 Model Context Protocol (MCP)
Model Context Protocol (MCP) é uma proposta de estrutura padronizada para representação e controle de contexto em interações com Modelos de Linguagem de Grande Escala (LLMs). Seu objetivo é organizar e persistir informações relevantes que enriquecem a compreensão do modelo ao longo de uma sessão interativa, promovendo continuidade, personalização e eficiência nas respostas.
Embora não realize busca externa como em RAG (Retrieval-Augmented Generation), o MCP complementa essa abordagem ao estruturar o contexto interno e facilitar a reutilização de informações em sessões subsequentes.
Características do MCP:
- Separar prompt e contexto: permite ao modelo diferenciar entre a instrução imediata do usuário e o conhecimento persistente (ex.: preferências, identidade, objetivos).
- Modularização de contexto: organiza dados em módulos lógicos como "perfil do usuário", "memória de longo prazo", "tarefas abertas" ou "histórico de conversa".
- Persistência e reuso de informações: permite que sessões futuras se beneficiem do contexto acumulado sem a necessidade de reintroduzir os dados.
Benefícios do uso de MCP:
- Reduz redundância na formulação de prompts.
- Melhora a coesão, consistência e personalização nas respostas.
- Suporta experiências interativas mais longas e sofisticadas, com continuidade entre sessões.
- Facilita o desenvolvimento de agentes multimodais, ferramentas colaborativas e fluxos de trabalho empresariais integrados.
Exemplos de uso:
- Agentes conversacionais com memória: que lembram preferências, interesses e estilo de comunicação do usuário.
- Plataformas corporativas: que carregam automaticamente contexto organizacional (equipe, projeto, documentos).
- Aplicativos produtivos e pessoais: que mantêm metas, tarefas, planos e progresso do usuário de forma persistente.
O MCP surge como uma camada essencial para o futuro das aplicações baseadas em LLMs, permitindo criação de experiências contextualizadas, fluentes e escaláveis.
5. Visão Computacional (Computer Vision)
Visão Computacional é a área da IA que busca ensinar máquinas a "enxergar" e compreender o mundo visual. Ela permite que sistemas interpretem imagens e vídeos para identificar objetos, reconhecer padrões e extrair informações úteis. Isso envolve desde operações básicas de processamento de imagem até redes neurais profundas especializadas em percepção visual.
5.1 Aplicações
Reconhecimento facial: utilizado em autenticação biométrica, vigilância, personalização de serviços e controle de acesso.
Leitura de placas (OCR): reconhecimento óptico de caracteres em documentos digitalizados, placas de veículos, notas fiscais, etc.
Diagnóstico por imagem: detecção de tumores, fraturas, ou anomalias em exames como radiografias, tomografias e ressonâncias magnéticas.
Classificação de imagens: categorização automática de imagens em tipos (ex.: animais, roupas, comidas).
Detecção de objetos: localização e classificação de múltiplos objetos em imagens/vídeos.
Segmentação semântica: identificação pixel a pixel de regiões específicas de uma imagem (ex.: separar estrada, pedestres e carros).
Reconstrução 3D: geração de modelos tridimensionais a partir de múltiplas imagens 2D.
Realidade aumentada e visão para robótica: percepção do ambiente para interação física e navegação autônoma.
5.2 Algoritmos e Arquiteturas
CNNs (Convolutional Neural Networks): redes que aplicam convoluções para extrair características espaciais como bordas, formas e texturas. São a espinha dorsal da maioria das aplicações de visão, especialmente em tarefas como classificação de imagens e detecção de padrões locais.
YOLO (You Only Look Once): modelo de detecção de objetos em tempo real que processa a imagem inteira de uma só vez, em vez de por regiões separadas. É amplamente utilizado em sistemas embarcados, drones e vigilância por vídeo.
RCNN (Region-based CNN): detecta objetos ao gerar propostas de regiões que podem conter objetos, e depois classifica essas regiões usando uma CNN. Evoluiu para variantes mais rápidas e precisas como Fast-RCNN, Faster-RCNN e Mask-RCNN (para segmentação).
U-Net: arquitetura simétrica com caminho de contração e expansão, muito utilizada em segmentação semântica, especialmente em imagens médicas, onde a precisão na delimitação de áreas anatômicas é crucial.
Transformers Visuais (ViT - Vision Transformers): aplicam atenção global ao processamento de imagens divididas em patches, substituindo convoluções por camadas de self-attention. Têm mostrado desempenho competitivo em benchmarks como ImageNet e COCO, principalmente em tarefas que exigem contexto mais amplo da imagem.
Essas arquiteturas são continuamente evoluídas e combinadas em pipelines robustos para resolver problemas visuais cada vez mais complexos, desde diagnóstico médico até carros autônomos.
Conclusão
Compreender os fundamentos da Inteligência Artificial e suas aplicações práticas é um passo crucial para dominar as tecnologias que moldam o presente e o futuro de diversas indústrias. Ao explorar suas ramificações — desde o aprendizado de máquina até redes neurais profundas, modelos de linguagem, visão computacional e técnicas de geração de conteúdo — é possível reconhecer o impacto transformador da IA em áreas como saúde, finanças, direito, marketing, educação, segurança e entretenimento.
A integração entre teoria e prática, entre conceitos matemáticos e implementações computacionais, permite criar sistemas cada vez mais inteligentes, adaptáveis e personalizados. Conhecer as diferenças entre modelos, os desafios técnicos envolvidos, e as possibilidades de expansão e especialização da IA é essencial para profissionais que desejam projetar soluções inovadoras, tomar decisões estratégicas com base em dados e acompanhar a rápida evolução tecnológica com embasamento sólido e visão crítica.
Dominar esses conceitos não é apenas uma exigência técnica, mas também uma oportunidade de compreender melhor o comportamento humano, os sistemas complexos e a construção de novas formas de interação entre pessoas e máquinas.